






 |
| Photo: Rafael Fernandes |
Yes, it's all about numbers and loads of operations which a computer is very good at. That’s the M in ML- what about the L?
Consider the gender recognition by voice dataset which can be found in this Kaggle page. The objective with this dataset is, when given a speech signal, to identify whether it is from a male or female. This challenge falls under the category of a classification problem. The objective here is to assign the class male or female given a speech signal, but classification problems don't necessarily have to be limited to two classes. Some other examples of classification problems are sentiment analysis of text (positive, neutral or negative), image identification (what kind of flower do you see in an image?), etc.
How could the computer learn to identify if a recorded voice is from a male or female? Well, if we want the computer to help us, in this case then we need to speak its language: numbers. In the machine learning world this means extracting features from the data. If you followed the Kaggle link above you can see that they already have extracted lots of features from the speech signal. Some feature examples are: mean frequency, median frequency, standard deviation of frequency, interquartile range, mean of fundamental frequency, etc. In other words, instead of having a time series showing the voice pressure signal, they extracted characteristics of this signal that may help us identify if the voice belongs to a male or female- this is called feature engineering. Feature engineering is a critical part of most machine learning processes.
I will pick two features of this dataset, namely the mean of fundamental frequency and interquartile range, and plot them in the figure below.
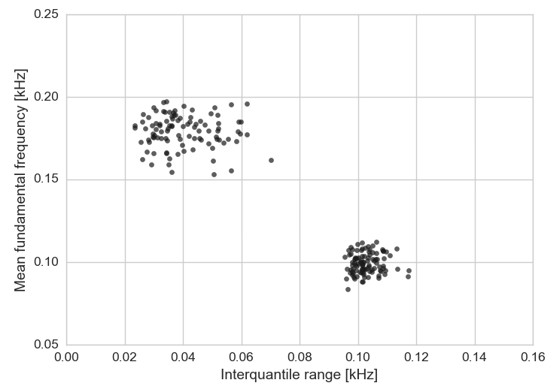
Two distinct groups of points appear in this figure. Knowing that this dataset comprises of speech signals from males and females, I guess that the group or cluster of points with higher mean fundamental frequency (higher pitch) belong to females whereas the other cluster belongs to males. Therefore, a possible way to identify which gender the signals belong to is to group the data into two clusters and assign the female label to the cluster with the higher mean fundamental frequency and the male label to the other cluster. It turns out that there are some ML algorithms that do exactly that- clustering. K-means is one of the most used algorithms to perform that operation, where the “K” in the algorithm name is the number of clusters that you want to identify (two in the current case). Notice that all this algorithm takes is an initial number of clusters you want to identify and the raw data and it returns a generic label (0 or 1, for instance), attached to each point, indicating which cluster each instance belongs to. In this case, it was my domain knowledge that assigned meaning to those labels.
Read more...
Source: InfoQ.com



